
INTRO
Virtualization-Based Security (VBS) has become one of the most significant architectural shifts in OS security of the past decade. The term itself is Microsoft’s — it describes a family of Windows security features that use the Hyper-V hypervisor to create isolated memory regions that the Windows kernel itself cannot tamper with. But the underlying ideas — using hardware virtualization to enforce security invariants that the OS cannot subvert — appear in both ecosystems, in very different forms.
Let’s describe and compare the modern security solutions on Windows and Linux:
- Threat Model
- Windows VBS Architecture
- Linux Security Architecture
- Confidential Computing
- Side-by-Side Comparison
- Deployment Context Analysis
- The Architectural Philosophy Difference
- References
Threat Model
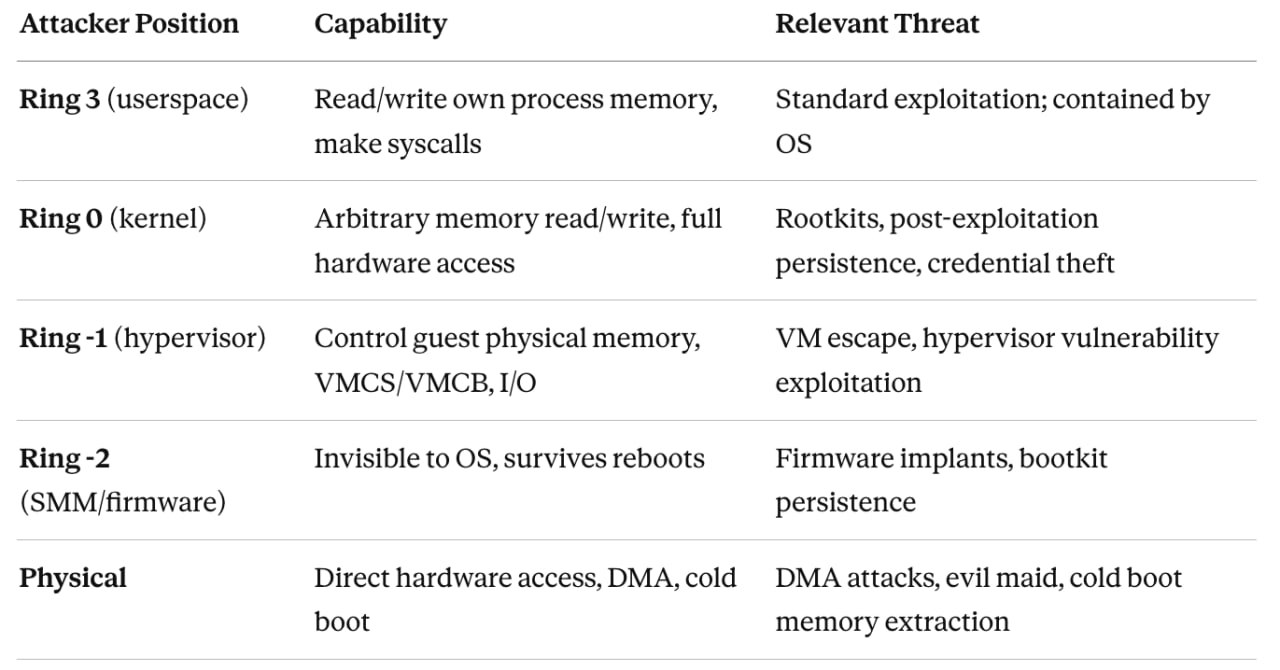
A classical OS security model (pre-VBS) only meaningfully defends ring-3 attackers. Kernel compromise is game over: the attacker owns memory, can patch code, dump credentials from LSASS, install unsigned drivers, disable security telemetry. The OS kernel is both the security enforcer and the attack target — a fundamental conflict of interest. VBS on Windows resolves this by moving the security enforcement boundary below the OS kernel. The hypervisor becomes the enforcer; the NT kernel becomes just another guest that cannot escape its constraints even with full ring-0 access. Linux’s security philosophy is different in emphasis: invest heavily in preventing kernel compromise in the first place, and use hardware features to make compromise harder rather than to contain post-compromise attackers. These both approaches have genuine merit and genuine blind spots.
Windows VBS Architecture
Virtual Trust Levels (VTLs)
The foundational concept in Windows VBS is the Virtual Trust Level. VTLs are an abstraction layer provided by the Microsoft Hyper-V hypervisor, layered on top of standard x86/ARM virtualization privilege levels (VMX root/non-root, exception levels on ARM).
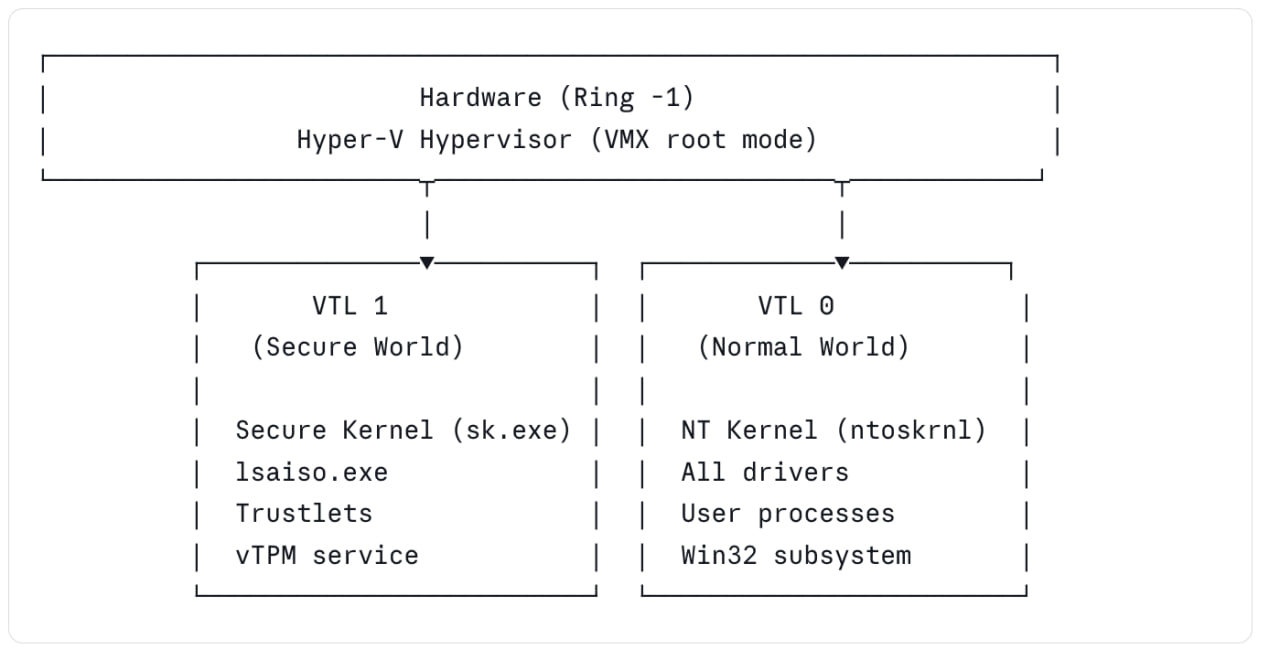
The hypervisor enforces the VTL boundary via Second Level Address Translation (SLAT — Intel EPT or AMD NPT). VTL1 can mark physical memory pages as inaccessible to VTL0 regardless of what page tables the NT kernel constructs. The NT kernel cannot see VTL1 memory even with MmMapIoSpace, MmGetPhysicalAddress, or any other kernel API. The constraint is enforced in hardware. VTL transitions (VTL 0 → VTL 1 and back) go through the hypervisor. There is no direct call gate. This means VTL1 code is protected not just from kernel memory reads, but from arbitrary code injection — VTL1 controls its own entry points entirely. One critical architectural decision: on Secured-core PCs, VTL1 is initialized before the NT kernel boots. The Secure Kernel establishes the SLAT restrictions, verifies the NT kernel image, and then releases control. This means even a compromised bootloader cannot retroactively disable VBS without being visible to the Secure Kernel’s measurement chain.
Hypervisor-Protected Code Integrity (HVCI)
HVCI is arguably the most significant individual component of Windows VBS from a kernel security standpoint. Its purpose is to ensure that the NT kernel can only execute code that has been cryptographically verified — and to make this guarantee hold even if the kernel itself is compromised.
The mechanism:
- At boot, the Secure Kernel (VTL1) configures SLAT so that no physical page is simultaneously writable and executable from VTL0’s perspective.
- When the NT kernel needs to make a page executable (for JIT output, driver loading, etc.), it must ask the Secure Kernel via a hypercall.
- The Secure Kernel (running in VTL1) evaluates the request: is this page backed by a signed, Microsoft-approved image? Does it pass KMCI (Kernel Mode Code Integrity) policy?
- If yes, the Secure Kernel updates the SLAT entry to grant execute permission.
- If no, the request is denied and the NT kernel cannot execute that code. The critical implication: even if an attacker achieves arbitrary kernel write (via a driver vulnerability, a race condition in a kernel subsystem, a memory corruption bug), they cannot make their payload executable. The W^X (Write XOR Execute) invariant is enforced at the SLAT level, which the NT kernel cannot modify. This closes the entire class of kernel shellcode injection attacks. HVCI also enforces that all kernel-mode drivers must be Microsoft-signed. An unsigned driver cannot be loaded, even by kernel code attempting to manually map it, because the resulting pages will never receive execute permission from the Secure Kernel.
HVCI does not protect against: data-only attacks. An attacker who can write to kernel data structures — token values, process privilege flags, EPROCESS fields — and achieve privilege escalation purely through data manipulation is not stopped by HVCI. This is a known limitation and an active research area. Return-oriented programming (ROP) chains using already-mapped kernel code are also not directly stopped (though PatchGuard and Control Flow Guard add additional friction).
Kernel Data Protection (KDP)
KDP extends the VBS model from code integrity to data integrity. Introduced in Windows 10 2004, KDP allows kernel components and drivers to mark memory regions as read-only via SLAT — enforced by the Secure Kernel.
There are two forms:
- Static KDP: A driver or kernel subsystem marks a region read-only at initialization time. The region cannot be modified afterward from VTL0, ever. Used for driver configuration structures, policy blobs, and security-critical kernel data.
- Dynamic KDP (via VslMarkInaccessiblePages): A page can be made write-protected dynamically.
From a practical security standpoint, KDP closes data-only attack paths against protected structures. Credential Guard uses KDP to protect its memory-mapped communication interface. WDAC policy blobs are KDP-protected. An attacker who modifies these from VTL0 cannot succeed — the write simply faults. Compare this to Linux’s __ro_after_init attribute, which marks kernel data read-only after initialization using standard page table permissions. It is effective against software bugs and accidental modification, but a kernel-level attacker who can manipulate page tables can bypass it. HVCI-enforced KDP cannot be bypassed from VTL 0 because the SLAT is not modifiable from VTL 0 by definition.
Credential Guard
Credential Guard is the most visible end-user feature of VBS. It isolates the Windows Local Security Authority (LSA) process — the component responsible for authentication, credential storage, and Kerberos ticket management — into VTL1 as a trustlet (lsaiso.exe, LSA Isolated). The normal LSA (lsass.exe) continues running in VTL0 as a stub. When operations requiring credential material are needed, lsass.exe makes requests to lsaiso.exe via a secure communication channel mediated by the Secure Kernel. The actual NTLM hashes, Kerberos TGTs, and derived key material never exist in VTL0 memory. The entire class of LSASS memory dumping attacks is defeated. An attacker with full kernel-level access to VTL0 cannot read VTL1 memory. The credentials are physically inaccessible.
Credential Guard does not protect: on-disk credential stores (SAM, NTDS.dit), credentials that flow through VTL 0 during network authentication, and smart-card-based credentials in some configurations. It specifically targets the in-memory credential cache problem, which is the primary enabler of lateral movement in pass-the-hash and pass-the-ticket attacks.
Secure Launch and DRTM
VBS’s security guarantees are only meaningful if the VBS initialization itself was not tampered with. This is the problem Secure Launch (also called DRTM — Dynamic Root of Trust for Measurement) addresses. Traditional Secure Boot establishes a static root of trust: the firmware verifies the bootloader, which verifies the OS kernel. This chain is established before any security software can observe it and depends entirely on firmware integrity. Firmware-level attacks (DXE driver tampering, UEFI rootkits) can subvert it. DRTM uses CPU hardware capabilities — Intel TXT or AMD SKINIT — to create a late launch event that cryptographically measures the hypervisor and OS loader in a way that is independent of firmware and verifiable via TPM PCR values. Even if the firmware is compromised, the TPM measurements taken during DRTM accurately reflect what is actually running. On Secured-core PCs, DRTM measurements are chained into the vTPM maintained by the Secure Kernel in VTL1, producing an attestable chain from hardware measurement through hypervisor initialization through Secure Kernel boot. Remote attestation can verify this entire chain.
Windows Defender Application Control (WDAC)
WDAC is the Windows kernel’s code execution policy enforcement mechanism. It operates via the Kernel Mode Code Integrity (KMCI) subsystem, which is in turn backed by HVCI when VBS is enabled. WDAC policy is expressed as a structured XML document, compiled to a binary blob (SIPolicy.p7b), and enforced by the kernel at image load time. Policies can allow/deny execution based on: publisher signature, file hash, file path (with caveats), PE attributes, and managed installer rules. When VBS is enabled, the active WDAC policy blob is KDP-protected — it cannot be modified at runtime even by kernel-level code. This is a key distinction from earlier AppLocker-based policies which were enforced by userspace processes that a kernel-level attacker could trivially disable.
Linux Security Architecture
Linux does not have VBS. It has no hypervisor-enforced code integrity boundary for the host kernel. What it does have is a layered set of mechanisms that together address overlapping (but not identical) threat surfaces.
Kernel Lockdown LSM
Kernel Lockdown (merged in Linux 5.4) is an LSM (Linux Security Module) that restricts what root-privileged userspace code can do to the running kernel. It has two modes:
- Integrity mode: Prevents userspace from modifying the running kernel. Blocks /dev/mem, /dev/kmem, raw I/O port access (ioperm/iopl), PCI BAR writes, loading unsigned kernel modules, kexec_load with unsigned images, hibernation (to prevent cold-boot attacks on RAM content), and debugfs interfaces that expose kernel internals.
- Confidentiality mode: Additionally restricts access to kernel memory that could expose secrets — PCIe config space, certain ACPI table access patterns, kernel core dumps.
Lockdown is automatically enabled when UEFI Secure Boot is active (if the kernel was built with CONFIG_LOCK_DOWN_IN_EFI_SECURE_BOOT), creating a chain: firmware verifies bootloader verifies kernel, and the running kernel refuses to load unsigned code or expose modification interfaces.
Critical distinction from HVCI: Lockdown is enforced by the kernel itself. A kernel-level attacker who has compromised the kernel can disable Lockdown by overwriting the relevant kernel data structures. It is a prevention mechanism, not a post-compromise containment mechanism. A sufficiently privileged attacker (kernel RW primitive) defeats it. HVCI cannot be defeated this way.
Integrity Measurement Architecture (IMA) and EVM
IMA is a kernel subsystem that measures files before they are accessed and extends the measurements into TPM PCR__s. This creates an auditable log of what code and data the kernel has loaded, verifiable by a remote attestation service. __IMA operates through LSM hooks at mmap, file_open, bprm_check_security, and similar points. For each measured file, it computes a hash, extends it into a TPM PCR, and (optionally) logs the event. IMA appraisal mode goes further: it checks that the hash of a file matches a hash stored in an extended attribute (security.ima), effectively providing file-level integrity enforcement.
EVM (Extended Verification Module) protects the IMA security.ima extended attributes themselves against tampering, using an HMAC keyed from a TPM-sealed key or an asymmetric signature. Without EVM, an attacker who can write to filesystem extended attributes could bypass IMA appraisal. In practice, IMA + EVM + TPM-backed key provides a measurement and appraisal stack that:
- Detects (via attestation) any unauthorized modification to measured binaries
- Prevents execution of files whose IMA hash does not match the stored value (in enforce mode)
- Roots trust in the TPM, not just the running kernel
This is conceptually related to what Windows DRTM + Secure Boot achieves, but without the hypervisor-enforced boundary. The measurement integrity is as strong as the TPM; the enforcement integrity is as strong as the kernel (which is weaker).
Integrity Policy Enforcement (IPE)
IPE was merged into the Linux kernel in version 6.9 and represents the closest Linux analog to Windows WDAC. It is a new LSM that enforces a policy-based code execution model at the kernel level. IPE policy is expressed in a simple declarative language and loaded into the kernel via a securityfs interface. Policy statements describe properties of files (dm-verity rooted integrity, IMA signature, specific digest) and operations (kernel module loading, executable mapping, script interpretation).
This policy would deny execution of any binary not backed by a dm-verity verified volume or without a passing IMA appraisal. The kernel enforces this policy at mmap/execve time via LSM hooks:
policy_name="production" policy_version=0.0.1
DEFAULT action=DENY
op=EXECUTE dmverity_rooted=TRUE action=ALLOW
op=KMODULE dmverity_rooted=TRUE action=ALLOW
op=EXECUTE appraise_result=pass action=ALLOW
Key differences from WDAC: IPE’s policy is not yet KDP-equivalent (cannot be protected against kernel-level modification in the same hardware-enforced way), and IPE is newer and less battle-tested. But architecturally, it demonstrates that Linux is moving toward the same kernel-enforced execution policy model that Windows has had since Device Guard.
eBPF LSM and Programmable Security Policy
Linux’s eBPF LSM (introduced in 5.7) enables security policy to be expressed as verified eBPF programs attached to LSM hooks. This has no equivalent in Windows.
A eBPF LSM program:
- Is written in restricted C, compiled to eBPF bytecode
- Is formally verified by the kernel’s eBPF verifier before loading: no unbounded loops, no invalid memory access, no side channels (with some nuance)
- Attaches to any LSM hook: file_open, bprm_check, socket_connect, task_kill, etc.
- Executes in kernel context with access to kernel data structures via eBPF helper functions
- Can be loaded and unloaded at runtime without kernel modules or reboots
For security product development — EDR sensors, policy enforcement engines, behavioral monitoring — eBPF LSM is extraordinarily powerful. You can implement per-process network policy, file access auditing, syscall argument inspection, and privilege escalation detection all as verified kernel programs that cannot crash the kernel and require no kernel module signing. The security risk is symmetric: eBPF programs run in kernel context and bugs in the eBPF verifier have historically been a significant kernel exploitation surface. The verifier ensures memory safety of the eBPF program, not correctness of the security logic. A eBPF LSM program that incorrectly allows an operation will silently fail open.
Kernel Hardening: CONFIG_STRICT_KERNEL_RWX and others
Linux’s kernel hardening configuration options implement software-enforced W^X and related invariants:
- CONFIG_STRICT_KERNEL_RWX: Kernel text is read-only and executable; kernel data is non-executable. Mapped via standard page table permissions (no SLAT backing).
- CONFIG_STRICT_MODULE_RWX: Same constraints applied to loaded kernel modules.
- CONFIG_DEBUG_WX: Warns if a W+X mapping is created at runtime.
- CONFIG_RANDOMIZE_BASE (KASLR): Randomizes the kernel’s virtual base address at boot. Weakens some exploitation primitives that rely on known kernel addresses.
- CONFIG_INIT_ON_ALLOC_USER_PAGES / CONFIG_INIT_ON_FREE_PAGES: Zero-initializes memory on allocation/free, preventing some information leaks.
- CONFIG_CFI_CLANG (Control Flow Integrity via Clang): Forward-edge CFI — validates that indirect function calls target valid function entry points.
- CONFIG_SHADOW_CALL_STACK (ARM64, Clang): Separate protected stack for return addresses, mitigating return address overwrites on ARM64 platforms.
These are all software-enforced. They significantly raise the bar for exploitation (particularly KASLR + CFI combinations) but a kernel write primitive can in principle bypass all of them given sufficient technique. That is the fundamental ceiling of kernel self-protection without a lower-privileged enforcement layer.
seccomp
seccomp (Secure Computing Mode) filters the set of system calls a process can make. In strict mode, only read, write, exit, and sigreturn are permitted. In filter mode (seccomp-BPF), a eBPF program runs on each syscall and returns a verdict (ALLOW, ERRNO, KILL). seccomp is a powerful userspace sandboxing primitive used by Chrome, Firefox, systemd, container runtimes, and many security-sensitive applications. It complements but does not replace kernel integrity mechanisms — it reduces the syscall attack surface for compromised processes but does not contain a kernel-level attacker.
Confidential Computing
Confidential computing solves a different problem from Windows VBS: rather than protecting the OS kernel from itself, it protects a VM’s memory from the hypervisor. This matters enormously in cloud environments where the hypervisor is operated by a cloud provider that tenants must trust.
AMD SEV, SEV-ES, and SEV-SNP
AMD Secure Encrypted Virtualization is a hardware technology built into processors:
- SEV: VM memory is encrypted with a per-VM key managed by the AMD Secure Processor (AMD-SP, a dedicated ARM Cortex-A5 running a TEE firmware). The hypervisor sees only ciphertext when accessing VM physical memory.
- SEV-ES (Encrypted State): Extends encryption to CPU register state on VMEXIT. The hypervisor cannot inspect register values during VM transitions.
- SEV-SNP (Secure Nested Paging): Adds integrity protection (not just confidentiality). The AMD-SP enforces that physical pages belonging to a VM cannot be remapped by the hypervisor to inject attacker-controlled content. Adds reverse map table (RMP) validation at the hardware level. Supports remote attestation — a VM can cryptographically prove to a remote party what code is running, what the launch measurement is, and that the memory is protected by SEV-SNP.
The Linux kernel has comprehensive SEV-SNP guest support (enabling Linux to run as a confidential VM) and host support (enabling KVM to run confidential VMs). Windows has some SEV support as a guest but the implementation depth and attestation tooling is significantly behind the Linux ecosystem.
Intel TDX (Trust Domain Extensions)
Intel TDX is Intel’s equivalent technology. Trust Domains (TD) are VM whose memory is encrypted and integrity-protected by the Intel Trust Domain Extensions hardware. The VMM (hypervisor) cannot read or modify TD memory; the hardware enforces this. TDX includes a remote attestation mechanism (Intel SGX-derived, using Intel’s Provisioning Certification Service) that allows a TD to prove its identity and launch measurement to a remote verifier without trusting the host platform.
Linux was the first OS with comprehensive TDX guest and host (KVM) support. The TDX Linux guest patches landed in 6.7/6.8. Microsoft has announced Windows TDX guest support but it trails.
ARM CCA (Confidential Compute Architecture)
ARM CCA introduces Realms — hardware-isolated VM-like containers that the hypervisor cannot inspect, enforced by the Realm Management Monitor (RMM) running at EL2. This is the ARM equivalent of AMD SEV-SNP/Intel TDX. Linux/KVM is the primary OS/hypervisor target for CCA. ARM itself develops and maintains the reference RMM implementation in collaboration with the Linux ecosystem.
Side-by-Side Comparison
Core Security Properties
| Property |
Windows VBS
|
Linux
|
|---|---|---|
| Kernel code integrity |
HVCI Hypervisor-enforced W^X via SLAT (EPT/NPT). Secure Kernel in VTL1 owns page execute permissions. Cannot be bypassed from ring 0 — even with arbitrary kernel write. |
CONFIG_STRICT_KERNEL_RWX Software-enforced via standard page tables. Bypassable with a kernel write primitive that can manipulate PTE entries. |
| Kernel data protection |
KDP SLAT-backed read-only data regions. NT kernel cannot modify them regardless of privilege. Used for WDAC policy blobs, Credential Guard comm buffers. |
__ro_after_init Page table-based; write-protected after init. Bypassable via kernel page table manipulation with sufficient exploit primitive. |
| Credential / secret isolation |
Credential Guard LSA runs as a trustlet (lsaiso.exe) in VTL1. NTLM hashes and Kerberos TGTs never exist in VTL0 memory. Full kernel compromise in VTL0 cannot read them. |
No equivalent All process memory is accessible to a ring-0 attacker. LSASS credential dumping (Mimikatz-class) is fully possible after kernel compromise. |
| Code execution policy |
WDAC / KMCI KDP-protected policy blob. Hypervisor-backed enforcement via Secure Kernel. Policy cannot be modified at runtime even by kernel-level code. |
IPE (≥ 6.9) Kernel-enforced LSM-based policy (dm-verity, IMA). Architecturally similar intent but not hypervisor-backed — policy not KDP-equivalent. |
| DMA protection |
Mandatory IOMMU Required for VBS. Device DMA into VTL1 memory is blocked by SLAT + IOMMU integration. Enforced as a Secured-core PC requirement. |
Configurable IOMMU Optional; CONFIG_IOMMU_DEFAULT_PASSTHROUGH off in hardened configs. Effective when enabled but not mandated by OS or hardware spec. |
| Kernel self-protection ceiling |
VTL1 holds post-compromise NT kernel compromise does not break the VTL1 security boundary. HVCI, KDP, and Credential Guard guarantees remain intact. |
No containment floor Kernel compromise defeats all kernel-mode protections. There is no enforcement layer below the kernel to contain a ring-0 attacker. |
| Secure boot chain |
DRTM DRTM (Intel TXT / AMD SKINIT) → Hyper-V → Secure Kernel → NT Kernel. Late-launch measurement independent of firmware integrity. |
UEFI Secure Boot UEFI Secure Boot → GRUB/shim → signed kernel. Static root of trust; firmware compromise can subvert it. No DRTM mandate. |
| Attestation |
vTPM in VTL1 DRTM-rooted PCR chain. vTPM operated by Secure Kernel; measurements reflect actual loaded code. Coherent end-to-end attestation for endpoints. |
IMA TPM measurements No unified stack on bare metal. Strong in CVM context (SEV-SNP / TDX): hardware-rooted attestation of confidential VM launch measurements. |
| Programmable security policy |
No equivalent No runtime-loadable kernel security programs. WDAC policy is static and requires offline authoring + signed update. |
eBPF LSM Verified eBPF programs attached to LSM hooks. Load / unload at runtime without kernel modules. No reboot. Used by EDR sensors and policy engines. |
| Confidential VMs |
Limited / trailing SEV-SNP and TDX guest support present but behind Linux ecosystem in depth and attestation tooling. Hypervisor (Hyper-V) is always trusted by design. |
First-class SEV-SNP, Intel TDX, ARM CCA guest and KVM host support. Full remote attestation tooling. Protects VM memory from a compromised hypervisor — Linux leads here. |
Attack Surface Comparison
Windows VBS-specific attack surface:
- Hyper-V vulnerabilities. VBS is only as strong as Hyper-V. Hyper-V has had VM escape vulnerabilities (e.g., CVE-2021-28476, a network virtualization RCE; CVE-2022-30190 tangentially; Hyper-V SVID vulnerabilities). A Hyper-V escape from VTL0 could compromise VTL1. This attack surface does not exist on systems without a hypervisor.
- VTL transition surface. The VTL transition path (VMCALL-based secure calls into VTL1) is a trust boundary that can be probed. The Secure Kernel’s syscall-equivalent interface must carefully validate all inputs from untrusted VTL0.
- Firmware/SMM attacks. System Management Mode (SMM) runs at a privilege level below the hypervisor on x86. A compromised SMM handler can potentially interfere with Hyper-V initialization or memory, though Secured-core PCs mandate SMM supervisor mode (WSMT) and SMM isolation validation.
- DXE driver attacks. UEFI DXE drivers run before Secure Launch. A malicious DXE driver can modify the environment that Hyper-V is launched into. Secured-core PCs require firmware compliance to address this, but older hardware running VBS without full Secured-core compliance is vulnerable.
Linux-specific attack surface:
- eBPF verifier bugs. The eBPF verifier is a complex piece of software that formally verifies eBPF programs before loading. Verifier bugs — incorrect type tracking, speculative execution side-channels, integer overflow in constraint tracking — have been a major kernel exploitation vector (CVE-2021-3490, CVE-2022-2785, CVE-2023-2163, etc.). Unprivileged eBPF (disabled by default in most distributions since ~5.16 via kernel.unprivileged_bpf_disabled=1) was an especially significant attack surface.
- io_uring and complex async interfaces. io_uring has been an extremely rich exploitation surface (multiple CVEs in 2022–2024). These complex kernel subsystems provide large attack surfaces that Linux does not mitigate with containment layers.
- Module loading. Despite CONFIG_MODULE_SIG_FORCE, loading kernel modules is a high-privilege operation with a long history of vulnerabilities. Lockdown prevents unsigned modules when Secure Boot is active, but this protection is software-enforced.
- Lack of post-compromise containment. The most fundamental difference: once ring-0 is achieved on Linux, there is no further containment layer below the kernel. The attacker owns the system. On Windows with HVCI, kernel compromise is real but the security guarantees of VTL1 remain intact.
Deployment Context Analysis
Enterprise Endpoint / Workstation
Windows VBS wins clearly here. The threat model is credential theft, ransomware, kernel rootkits, and post-exploitation lateral movement. HVCI stops kernel shellcode injection. Credential Guard defeats LSASS dumping. WDAC enforces a known-good execution policy. All enforced with hardware guarantees that survive kernel compromise. Linux has no answer to “kernel-level attacker dumps all in-memory secrets”. The __LSM __stack is excellent for prevention, but prevention is a ceiling, not a floor.
Cloud Multi-Tenant Infrastructure
Linux leads. The relevant threat model is tenant isolation, hypervisor compromise, and side-channel attacks (Spectre-class, L1TF, MDS). SEV-SNP and TDX on KVM provide cryptographic isolation of VM memory from the hypervisor with hardware attestation. Linux’s support for these technologies — both as a guest and as a KVM host — is first-class and years ahead of Windows. Windows VBS trusts the hypervisor by definition. In a cloud scenario where you do not own the hypervisor, VBS provides no protection against a compromised hypervisor.
Container/Serverless Workloads
Mixed, with Linux-specific tooling advantage. Linux’s eBPF LSM, seccomp, namespaces, cgroups, and Landlock provide a highly composable sandboxing stack for container workloads. Kata Containers uses KVM-based VM isolation for containers. gVisor provides a userspace kernel sandbox. These are Linux-native technologies with no direct Windows equivalent in the container ecosystem.
Embedded / IoT
Neither dominates; hardware varies. ARM Cortex-A platforms running Linux have access to TrustZone-based TEEs (OP-TEE), IMA, and Secure Boot chains. ARM Cortex-M and RISC-V embedded targets have platform-specific security features. Windows IoT Core and Windows IoT Enterprise bring VBS to some embedded platforms but with significant hardware requirements. The relevant comparison here is OP-TEE vs. VTL1 Trustlets, which deserves its own article.
The Architectural Philosophy Difference
Windows VBS is a post-compromise containment architecture.
It accepts that the NT kernel may be compromised and designs a system where compromise does not mean total failure. This is a mature, pragmatic, and powerful approach. It solves the real-world problem that motivated attackers will find kernel vulnerabilities, and “don’t have any kernel vulnerabilities” is not a sufficient security policy.
Linux is a prevention-depth architecture.
Its philosophy is to make kernel compromise as difficult as possible through a layered set of mechanisms — Lockdown, IMA, IPE, kernel hardening configs, KASLR, CFI, seccomp, eBPF LSM. Each layer independently raises the bar. The bet is that sufficiently many independent prevention layers will keep sophisticated attackers out. When they fail — and they do fail — there is no containment floor.
Neither philosophy is obviously correct. The Microsoft approach requires trusting Hyper-V and the Secure Kernel, which adds their own attack surfaces. The Linux approach requires trusting that prevention will hold, which is a strong assumption against sophisticated, persistent adversaries. What is observable from CVE history and public exploitation: Windows HVCI has proven very difficult to defeat in practice (most “HVCI bypass” techniques in the wild are actually Secure Boot or firmware-level attacks, not direct SLAT manipulation). Linux kernel exploitation remains active and productive as an attack vector, though LTS kernel hardening has significantly raised the cost.
References
- Microsoft VBS Documentation — Microsoft Learn
- Virtualization Based Security
- PatchGuard Peekaboo: Hiding Processes on Systems with PatchGuard in 2026
- From hardware virtualization to Hyper-V’s Virtual Trust Levels
- Living The Age of VBS, HVCI, and Kernel CFG
- Abusing VBS Enclaves
- Secure Enclaves for Offensive Operations
- Linux Kernel Lockdown LSM
- Linux IMA/EVM Documentation
- Linux Integrity Policy Enforcement
- Linux eBPF LSM
- AMD SEV-SNP
- Intel TDX